
Australia’s Treasurer is about to present the nation’s mid-year figures, and all bets are on another few billion in reduced revenue. If you use data to make decisions of any kind, fear this: how well your model works with data you haven’t seen.
Just remember though, the mid-year financial story will be old hat. We’ve been hearing about unexpected revenue write-downs at regular six-month intervals, ever since the Global Financial Crisis emerged in 2008. Reflecting on this, I decided to go through the seven Budget Papers since 2008-09 to see what the Treasury forecasts have been like.
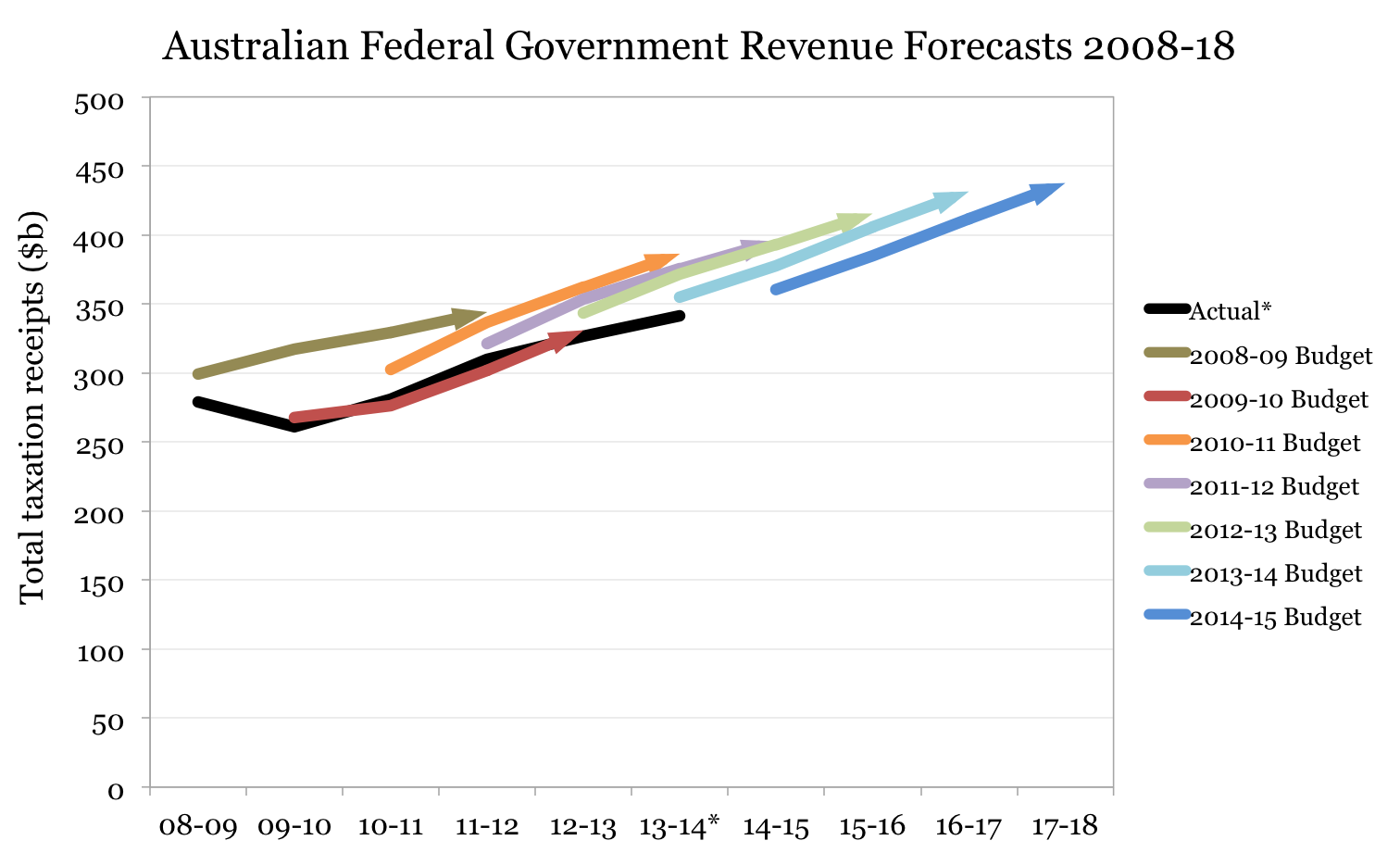
All except one of the four-year forecasts (the “forward estimates”, that stupefying term) were erroneously optimistic, each based on expected economic conditions from prior experience. Only the 2009-10 forecasts proved accurate, which is telling: in early 2009, amidst so much uncertainty, no economic forecaster would have been crazy enough to copy the past.
In data analysis, only accuracy with unseen data really matters. Whether you are an economic forecaster, medical statistician or just a casual observer of patterns, you create models of the world using the tiny amount of data you’ve collected and seen. That’s the easy part, but if the model you’ve created doesn’t fit the real world well (tomorrow’s profit, or the larger patient population), it’s useless, and perhaps even harmful.
Unseen data used to keep me awake at night (literally) when I was creating Cochlear Limited’s first intelligent system a decade ago (AutoNRT™). In my possession were 5,000 measurements of auditory nerve activity given by experts. I used a machine learning technique to create an automated expert system from the data, but no matter how fancy the modelling, the performance of the system hinged on how representative the 5,000 measurements were of the real world.
As it turned out, the dataset was too clean and optimistic, lacking certain types of strange looking measurements. I never quite found out why those measurements were originally absent, but they turned up again and again during the first trials of the system.
For months afterwards I wondered what other unseen data might cause problems, but after the inclusion of a good sample of the strange data and a rebuilding of the system, AutoNRT became accurate enough to succeed commercially for years.
If you work with data, these two practices are fundamental to your success:
1. Always be sceptical of how representative your dataset is. Good samples always trump clever mathematics. Think very carefully about how your data were collected, and how they may differ from data produced in the future. In 2009, Nature celebrated Google Flu Trends, but by 2013, our web search patterns had changed and Nature News reported inaccuracies as large as a factor of two. (And while we’re on the subject, in 2013 we started hearing about Google’s tax practices when government tax receipts just kept missing their forecasts.)
2. Always evaluate the performance of your models on unseen data. The accuracy over your existing data (the “training set”) is almost always far better than the accuracy over unseen data (the “test set”). Only accuracy with the test set really matters. Running repeated trials with newly collected data will give an honest assessment of your model, and furthermore, adding the new data may even improve the representation of your training set.
* 2013-14 result is an estimate, pending further receipts. References: Budget Paper No. 1: Budget Strategy and Outlook (Statement 5: Revenue), 2008-09 to 2014-15.








